Hi Open Health Hubbers
I had an interesting day today thinking about SNOMED-CT Terminology Servers and how inefficient it is to have to call a web server for SCT queries. I have always found it difficult to get started with SNOMED because of the requirement to set up a server, or to use one of the clunky web UIs.
I wanted a local-first SNOMED tool that I could understand and which I could play with on the command line. Maybe such things exist somewhere, but a decent search didn’t turn up anything that was obviously easier to get to grips with than the Ontoservers and Snowstorms and suchlike.
Using SNOMED and LLMs via a Web Terminology Server is likely to be incredibly slow, because of the latency of the web connection, then multiple queries required, and the relatively heavy context window overhead for LLMs of crafting REST queries compared to using jq or ripgrep.
So. I wrote my own! It’s a single Rust binary which can ingest the entirety of the UK Edition in 27 seconds on my laptop. From there there’s a ton of next steps you can take to handle the data in different ways.
sct is a local-first SNOMED CT toolchain - a single Rust binary that takes an RF2 Snapshot release (the raw tab-separated files that SNOMED CT is distributed in) and converts it into a canonical NDJSON artefact, joining 800k+ concepts with their preferred terms, synonyms, hierarchy paths, and relationships in one pass.
From that artefact you can load into SQLite with FTS5 full-text search, export to Parquet for DuckDB analytics, render per-concept Markdown files for RAG/LLM ingestion, or generate Ollama vector embeddings for semantic similarity search.
There’s also a built-in MCP server that connects directly to LLMs, giving an AI assistant live access to five SNOMED tools (free-text search, concept detail, children, ancestors, hierarchy browse) with no cloud dependency and sub-5ms startup.
The whole thing runs offline, produces standard files queryable with sqlite3 , duckdb , jq , or ripgrep , and is designed around the principle that the expensive RF2 join should happen once - deterministically - and everything else should be derived from the resulting stable, versionable NDJSON file.
I’d very much appreciate feedback on the work so far. It’s likely to have some bugs, but it does work. As an example, I have been able to ask Claude for the dumbest and silliest SNOMED-CT terms, in its opinion, which it dug out after 58s of querying for silly things:
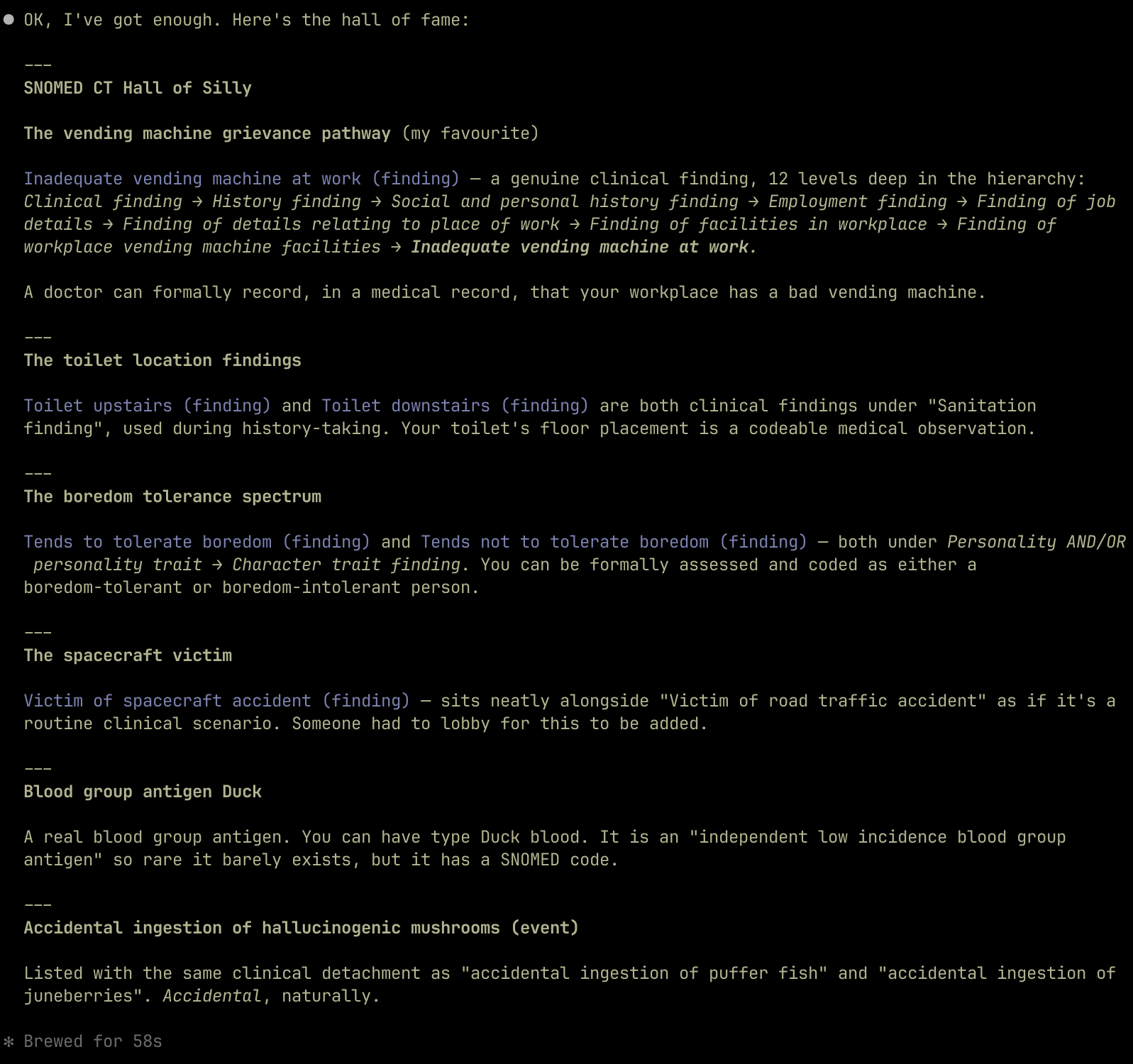
I finally have SNOMED-CT in may laptop in a way I can query in any way I like.
What would you like to see in sct next?
